What is Attention in Deep Learning?
June 19, 2024
In this article, I will attempt to motivate the need of Attention in Deep Learning. I will explain the intuition behind it, talk about it's history and throw some light on different applications of Attention in Natural Language and Vision models.
What is Attention?
Attention in deep learning allows models to focus on important parts of input data, much like humans do. This mechanism enhances tasks such as image captioning and language translation by improving the encoding of relevant features. To get an intuition behind Attention, lets consider a task of Image Captioning. When we humans try to understand an image, we like to focus on different parts of the image as we try to understand it. However, earlier versions of the Computer Vision and Natural Language models didn't use this principle. The entire image would be encoded into a fixed size vector and that vector would then be used for downstream tasks, like Image Captioning. Something like below.
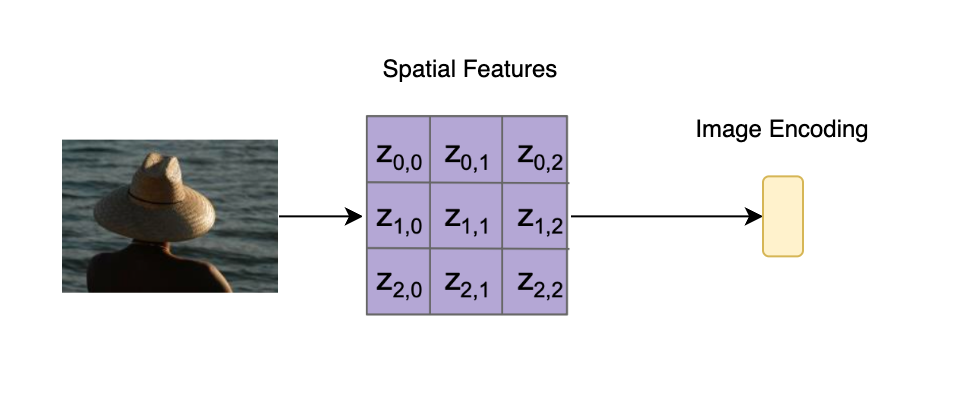
Similarly, for Natural language, the earlier versions of Deep Learning models would encode the entire text in a fixed size vector for downstream tasks, like translation or sentiment analysis.
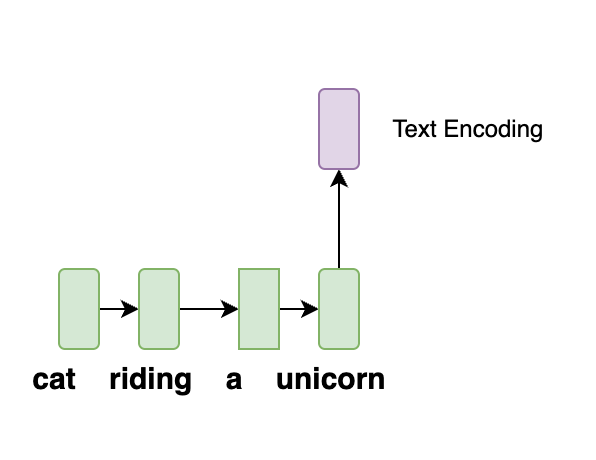
To motivate the problem a bit more, lets assume we are given the task to detect objects from the below image.
 Source: https://pngtree.com/
Source: https://pngtree.com/
The task becomes more difficult if we are only allowed one single pass of the image like below while remembering the objects as we see them.

We can see that it is relatively easy to reason about the image when we have access to the image features where we can focus on. Similarly, lets consider below sentence.
I can't believe I saw a cat riding a unicorn in the sky!
If we were only allowed to look at this sentence one word at a time in a single pass, with a limited storage space to encode the meaning of the sentence, that encoding can become a bottleneck of how much contextual meaning it can store. Clearly, there was a need for a better mechanism to encode the features which would let the Deep Learning models focus on different part of the features for downstream tasks.
This is where Attention Mechanism came to the rescue of AI researchers.
History and Evolution of Attention
Attention was first introduced by Bahdanau et. al. in 2014 in the context of Neural Machine Translation. It was later adopted in Vision by Xu et. al. in 2016. The real breakthrough came in 2017 when Vaswani et. al. introduced the Transformer architecture which used the concept of Attention and helped parallelize the computation to leverage the parallel compute of the GPUs (Graphics Processing Units). Since then, the concept of Attention has been widely adopted in various NLP and Vision models.
Lets take a closer look at these milestones to understand their evolution.
Neural Machine Translation: In the context of Neural Machine Translation, the task is to translate a sentence from one language to another. But the ordering of the words can be different in different languages. For example, consider the English sentence - "The agreement on the european economic area was signed in August 1992". Its French translation is "L'accord sur la zone économique européen a été signé en août 1992".
In this case, the word "european economic area" is translated to "zone économique européen", which is essentially reversed. Attention visualisation helps us understand how the model is focusing on different parts of the sentence to translate it. In the below image, we can see how the the model is focusing on Area for Zone, Economic for économique and European for européen.
When compared to earlier method, the proposed method encoded the sentence by weighing the parts of the sentence by relevance. For example, in the below image, we can see that the model would put higher emphasis on unicorn simply by having a larger attention score.
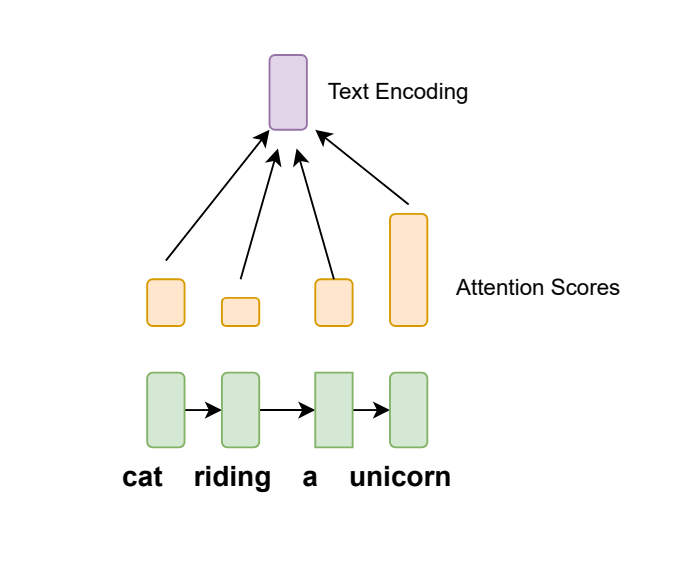
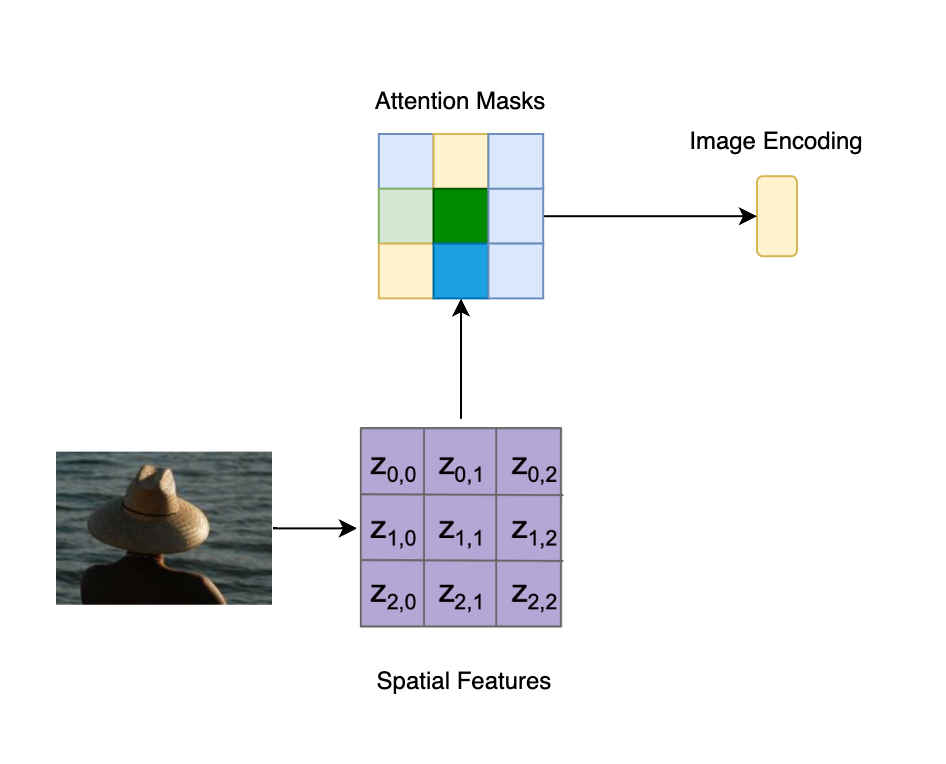
Image Captioning: In the context of Image Captioning, the task is to understand the context of objects in the image and extract relevant information from it. In the below image, we can see how the model is focusing on different parts of the image to understand it better.
 Source: Show, Attend and Tell by Xu et al., 2016
Source: Show, Attend and Tell by Xu et al., 2016
We can see that the vision model is able to focus on different parts of the image when generating the underlined word in the caption. These Attention Masks are used for visualisation purposes and help us understand how the model is focusing on different parts of the image, when generating an output word in the caption.
Transformer: Transformer architecture used similar mechanism of Attention Scores and helped parallelize the computation to leverage the parallel processing of the GPUs. This enabled us to train larger models and scale them to larger datasets and helped in achieving state of the art results in various NLP and Vision tasks. The mechanism allows for richer representation of the data and also allows us to train it efficiently across parallel compute. We can see that in the below image, how the model is focusing on different parts of the sentence.
We can see how the word it_ is focusing on The_ animal_ and tired_.
Conclusion
Attention mechanisms have significantly advanced deep learning, allowing models to focus on important data aspects and enhancing performance across NLP and vision tasks. Personally for me, the biggest takeaway from the evolution of this simple concept is how the research community builds on top of each other's work and continue to push the boundaries of what is possible.
_ _ _ _
Thank you so much for taking time to go through this.❤️ If you feel there is some typo in this article, or some of the content can be improved, please feel free to Edit this Post. Or you can go back to continue reading other articles. 😀